

")
For nearly two decades, Indian geneticists harboured a quiet frustration: while the world chased genomic breakthroughs, the billion-plus people of this subcontinent remained largely genomically invisible to science.The global genetic databases doctors and drug developers use to decode diseases, predict risks, and tailor treatments are, as one geneticist put it, “extremely Eurocentric”. Few databases capture Indian genetic variations, Bratati Kahali, geneticist and computational biologist at the Indian Institute of Science and principal investigator in the GenomeIndia Project, told The Scientist.That invisibility carried real consequences. For Indian patients, drug dosages, efficacy forecasts, and risk profiles — all were calibrated to someone else’s genome.That gap is now, at least partially, being closed.
What a Genome actually is
Your genome is the complete instruction manual for building and running you. It is the entire set of genetic material, DNA, present in an individual, containing all the information necessary for development, functioning, and maintenance of that organism. In humans, that instruction manual runs to more than three billion chemical base pairs, written in a four-letter alphabet — A, T, C, G — coiled up inside nearly every cell in your body.Genome sequencing is the process of reading that manual, letter by letter. What makes it medically significant is that roughly 0.1 percent of that sequence differs between any two people. These genetic variations among individuals are crucial for understanding disease predispositions and rare inherited disorders. They determine our response to drugs and help track migration and evolutionary patterns of population groups. The problem, historically, has been that those reference maps of human genetic variation were built largely from European populations. A 2022 study revealed that participants of European ancestry accounted for 86.3% of genome-wide association studies, a method for identifying genetic markers linked to diseases or traits, while South Asian populations contributed far less. For a country like India, with its extraordinary genetic complexity, this was not just a scientific inconvenience. It was a structural problem in healthcare.
Why India is genetically unlike anywhere else
India is not one population. It is, more accurately, hundreds of populations living alongside each other, shaped by thousands of years of migration, adaptation, and- cruciall- a social structure that kept communities remarkably separate from one another.The Indian population comprises more than 4,600 population groups, and several thousand of them are endogamous – meaning people within these communities have, for generations, married within their own group. The consequences of this for genetics are profound. When a community practices endogamy over centuries, rare disease-causing mutations that might be diluted out in a more mixed population instead get amplified and passed down. Some communities carry elevated risks for specific diseases that the broader medical world hasn’t studied, simply because no one had looked closely enough at their genomes.India has one of the most genetically diverse populations in the world, with over 4,600 distinct groups. Due to this, some populations have unique genetic markers that may increase susceptibility to certain diseases or affect responses to specific drugs. The challenge wasn’t just that Indian genomes were understudied globally. It was that findings from genetic research in Europe, America, or East Asia couldn’t be reliably applied to Indians — their biology and risk profiles diverged sharply. Picture a doctor treating Type 2 diabetes in rural Tamil Nadu, relying on tools calibrated for someone in Manchester.
The GenomeIndia Project: What was done
In January 2020, the Department of Biotechnology (DBT) under India’s Ministry of Science and Technology launched the GenomeIndia Project- a coordinated national effort to do what had never been done at scale: sequence the genomes of a representative sample of Indians and build a reference database that actually reflected this country’s genetic reality.More than 20 illustrious research institutions, including IISc, IITs, CSIR, and DBT-BRIC, played a major role in the research. The project was spearheaded by the Centre for Brain Research (CBR) at the Indian Institute of Science in Bengaluru, and involved institutions spread across the country- from CSIR-CCMB in Hyderabad to the National Institute of Biomedical Genomics in Kolkata.
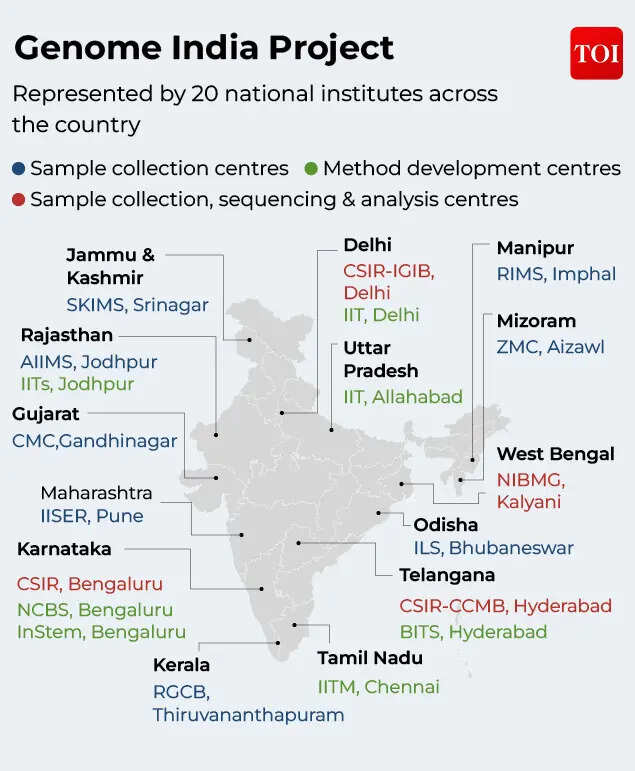
The dataset was drawn from 83 population groups and represented equitably, with 36.7% of the samples collected from rural populations, 32.2% from urban populations, and 31.1% from tribal populations. The genomes of India’s four major linguistic families — Indo-European, Dravidian, Austro-Asiatic, and Tibeto-Burman — were all included. Participants were healthy, unrelated individuals, and the project collected over 20,000 blood samples, which are now stored in a biobank at CBR in Bengaluru.Then came the actual sequencing and this is where the scale of what India pulled off becomes apparent. Technological advancement in this field has been remarkable: the first whole genome project required 13 years and $3 billion to complete, whereas this project sequenced genomes in 3-4 months per batch. The falling cost of sequencing technology made the project financially feasible, and the institutional network made it logistically possible even as Covid-19 disrupted the timeline midway through.
Where the project stands today
In February 2024, the Department of Biotechnology officially announced the completion of whole genome sequencing of 10,074 individuals. The project successfully sequenced the genomes of 10,000 individuals, archived at the Indian Biological Data Centre portals. A biobank housing 20,000 blood samples has been established at the Centre for Brain Research, IISc, to support future research endeavours. The completion was marked with a significant event in January 2025, when Prime Minister Narendra Modi addressed the Genomics Data Conclave at Vigyan Bhavan, calling it a historic step in the world of research. The data consisting of the genome sequences of 10,000 Indians was made available at the Indian Biological Data Centre, and researchers and scientists can now use it to understand India’s genetic landscape.The data is housed at the Indian Biological Data Centre (IBDC) in Faridabad, India’s first national life science data repository, and access is governed by the FeED Protocol (Framework for Exchange of Data), which was launched alongside the GenomeIndia Data Conclave to ensure responsible, transparent data sharing.Then, in April 2025, the preliminary scientific findings were published in Nature Genetics, bringing the project’s work into the peer-reviewed record. Preliminary findings of the GenomeIndia project revealed 180 million genetic variants from 9,772 individuals across India. The project identified around 130 million genetic variants, including over 44 million previously unknown variants that were not present in global databases. Of the 27 million rare variants identified, 7 million are novel and not found in global databases at all, highlighting India’s unique genetic landscape.

What the findings actually mean
The most immediate medical implications are in pharmacogenomics – the study of how our genes affect how we respond to drugs. The researchers observed that many Indian populations carry several gene variants implicated in reducing the efficiency and efficacy of antiviral drugs. The project identified 38 critical genetic variants that impact drug metabolism. This is not a small finding. It means that for a significant portion of the Indian population, the standard doses of certain medications may not work as intended — either under-treating or over-treating patients because the drug guidelines were derived from populations with different metabolic genetics.The implications for disease risk are equally significant. Researchers linked many of the rare variants to diseases such as hypertrophic cardiomyopathy, hypercholesterolemia, and cancers. The project also made progress on understanding genetic links to conditions like thalassemia, sickle cell anemia, particularly prevalent in tribal communities, and neurological disorders like muscular dystrophies and epilepsy.Then there is the matter of what scientists call population history. Because endogamy has kept Indian communities genetically distinct from one another for centuries, the genomes carry signatures of ancient migrations and admixtures. Genetic signatures provide clues to ancient migrations and ancestry; India has around 4,000 endogamous groups with minimal gene flow between them. In effect, reading these genomes is also a way of reading India’s history- the movements of peoples, the formation of communities, the biological imprint of social structures that are thousands of years old.
The unfinished work
It would be a mistake to read the project’s completion as the end of the story. It is, more precisely, the end of Phase One.The 10,000 genomes sequenced represent approximately 2% of India’s documented 4,600 population groups. Programs like the USA’s All of Us initiative aim to enroll at least 1 million participants from historically underrepresented populations, representing 0.3% of the national population. Similarly, the UK’s 100,000 Genomes Project represents 0.15% of the country’s diverse population. By comparison, GenomeIndia currently covers approximately 0.007% of the population.Union minister of state (independent charge) for science and technology Dr Jitendra Singh announced a future target of sequencing 10 million genomes to accelerate India’s advancements in genomics and personalised medicine. Whether the funding, infrastructure, and institutional coordination required to reach that number will materialise is an open question. But the ambition reflects a genuine understanding within government that the 10,000 genomes are a foundation, not a ceiling.There are also real challenges that the project has surfaced rather than solved. Many Indian genomic samples are sent abroad for sequencing, as existing regulations allow commercial export of biological samples, raising concerns about data security and privacy. The genomic data of entire communities- their disease risks, their ancestry, their biological vulnerabilities- sitting in databases requires careful governance. The massive dataset generated, 8 petabytes, poses significant challenges in terms of storage, management, and data security. Ethical questions around informed consent are not trivial either. Genomic data is unlike other personal data, it implicates not just the individual whose sample was taken but their entire family. When a community’s genetic vulnerabilities are mapped, that information can be misused for insurance discrimination, stigmatisation or purposes that the original participants never consented to.
The larger bet
What India is doing with the GenomeIndia Project is placing a long bet that the future of medicine is personalised and that being part of that future requires owning your own data. India’s bioeconomy has surged from $10 billion in 2014 to over $130 billion in 2024, with projections to hit $300 billion by 2030. India now ranks 12th globally in biotech and 3rd in the Asia-Pacific region. The GenomeIndia Project is part of that larger ambition. India produces nearly one-fifth of the world’s generic medicines and runs one of the world’s largest pharmaceutical industries. But its drug development has historically been derivative, making cheaper versions of medicines discovered elsewhere, for diseases profiled elsewhere, in populations that are not Indian. A national genomic database changes the terms of that equation.States are beginning to move too. Gujarat has become the first Indian state to launch a tribal genome sequencing project, an initiative to enhance health and well-being of tribal citizens. The Gujarat Biotechnology Research Centre will sequence the genomes of 2,000 individuals from the tribal population in 17 districts, with the aim of identifying genetic markers for natural immunity, cancer, and hereditary diseases such as sickle cell anaemia and thalassemia.A country of 1.4 billion people, extraordinary genetic diversity, and a documented problem with diseases that the rest of the world’s research establishment hasn’t fully studied, that is simultaneously India’s challenge and its scientific opportunity. The GenomeIndia Project has, for the first time, given the country a foundation to act on that opportunity. What happens next depends on whether India can translate that foundation into medicine, policy, and research infrastructure that actually reaches the people whose genomes made the project possible in the first place, the rural farmer in Odisha, the tribal community in Gujarat, the Tibeto-Burman speaker in Arunachal Pradesh.






Leave a Reply